// src/runtime/proc.go // The bootstrap sequence is: // // call osinit // call schedinit // make & queue new G // call runtime·mstart // // The new G calls runtime·main. // 启动顺序 // 调用 osinit // 调用 schedinit // make & queue new G // 调用 runtime·mstart // 创建 G 的调用 runtime·main. // // 初始化sched, 核心部分 funcschedinit() { ...
// 网络的上次轮询时间 sched.lastpoll = uint64(nanotime()) // 设置procs, 根据cpu核数和环境变量GOMAXPROCS, 优先环境变量 procs := ncpu if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 { procs = n } // 调整 P 的数量,这时所有 P 均为新建的 P,因此不能返回有本地任务的 P if procresize(procs) != nil { throw("unknown runnable goroutine during bootstrap") }
// g0 stack won't make sense for user (and is not necessary unwindable). // 检查当前 g 是否是 g0,g0 栈对用户而言是没有意义的(且不是不可避免的) if _g_ != _g_.m.g0 { callers(1, mp.createstack[:]) }
// 锁住调度器 lock(&sched.lock) // 确保线程数量不会太多而溢出 if sched.mnext+1 < sched.mnext { throw("runtime: thread ID overflow") } // mnext 表示当前 m 的数量,还表示下一个 m 的 id mp.id = sched.mnext // 增加 m 的数量 sched.mnext++ // 检测 m 的数量 checkmcount()
// 初始化 gsignal,用于处理 m 上的信号。 mpreinit(mp) // gsignal 的运行栈边界处理 if mp.gsignal != nil { mp.gsignal.stackguard1 = mp.gsignal.stack.lo + _StackGuard }
// Add to allm so garbage collector doesn't free g->m // when it is just in a register or thread-local storage. // 添加到 allm 中,从而当它刚保存到寄存器或本地线程存储时候 GC 不会释放 g->m // 每一次调用都会将 allm 给 alllink,给完之后自身被 mp 替换,在下一次的时候又给 alllink ,从而形成链表 mp.alllink = allm
// NumCgoCall() iterates over allm w/o schedlock, // so we need to publish it safely. // NumCgoCall() 会在没有使用 schedlock 时遍历 allm,因此我们需要安全的修改。 // 等价于 allm = mp atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp)) // m 的通用初始化完成,解锁调度器 unlock(&sched.lock)
// Allocate memory to hold a cgo traceback if the cgo call crashes. // 分配内存来保存当 cgo 调用崩溃时候的回溯 if iscgo || GOOS == "solaris" || GOOS == "windows" { mp.cgoCallers = new(cgoCallers) } }
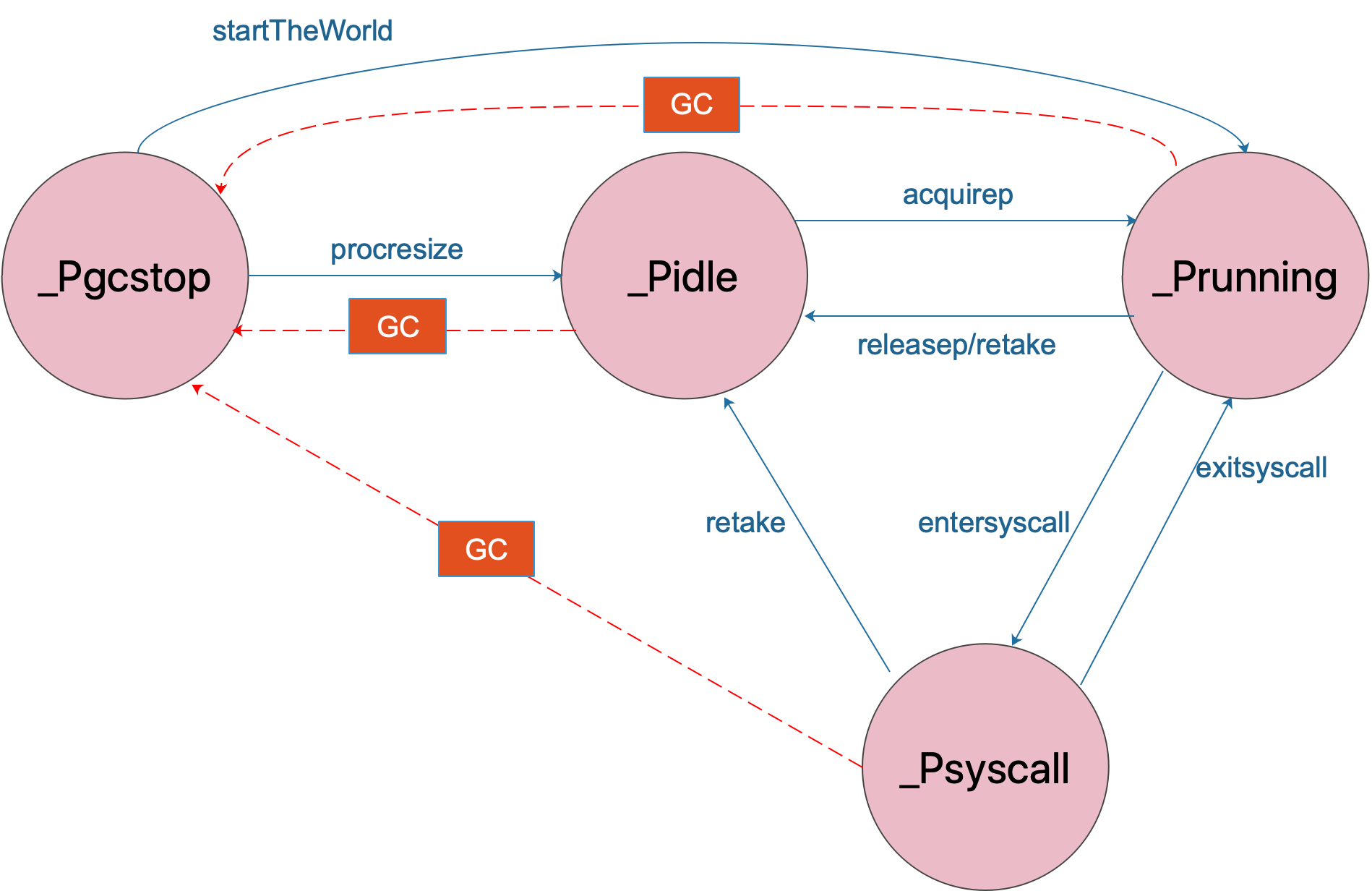
// src/runtime/proc.go // Change number of processors. The world is stopped, sched is locked. // gcworkbufs are not being modified by either the GC or // the write barrier code. // Returns list of Ps with local work, they need to be scheduled by the caller. // 修改 P 的数量,此时所有工作均被停止 STW,sched 被锁定。 gcworkbufs 既不会被 GC 修改,也不会被 write barrier 修改。 // 返回带有 local work 的 P 列表,他们需要被调用方调度。 funcprocresize(nprocs int32) *p { // 获取之前的 P 个数 old := gomaxprocs // 边界检查 if old < 0 || nprocs <= 0 { throw("procresize: invalid arg") } // trace 相关 if trace.enabled { traceGomaxprocs(nprocs) }
// update statistics // 更新统计信息,记录此次修改 gomaxprocs 的时间 now := nanotime() if sched.procresizetime != 0 { sched.totaltime += int64(old) * (now - sched.procresizetime) } sched.procresizetime = now
// Grow allp if necessary. // 必要时增加 allp // 这个时候本质上是在检查用户代码是否有调用过 runtime.MAXGOPROCS 调整 p 的数量。 // 此处多一步检查是为了避免内部的锁,如果 nprocs 明显小于 allp 的可见数量,则不需要进行加锁 if nprocs > int32(len(allp)) { // Synchronize with retake, which could be running // concurrently since it doesn't run on a P. // 此处与 retake 同步,它可以同时运行,因为它不会在 P 上运行。 lock(&allpLock) if nprocs <= int32(cap(allp)) { // 如果 allp 容量足够,去切片就好了 allp = allp[:nprocs] } else { // 否则 allp 容量不够,重新申请 nallp := make([]*p, nprocs) // Copy everything up to allp's cap so we // never lose old allocated Ps. // 将所有内容复制到 allp 的上,这样我们就永远不会丢失旧分配的P 。 copy(nallp, allp[:cap(allp)]) allp = nallp } unlock(&allpLock) }
// initialize new P's // 初始化新的 P for i := int32(0); i < nprocs; i++ { pp := allp[i] // 如果 p 是新创建的(新创建的 p 在数组中为 nil),则申请新的 P 对象 if pp == nil { pp = new(p) pp.id = i // p 的 id 就是它在 allp 中的索引 pp.status = _Pgcstop // 新创建的 p 处于 _Pgcstop 状态 pp.sudogcache = pp.sudogbuf[:0] for i := range pp.deferpool { pp.deferpool[i] = pp.deferpoolbuf[i][:0] } pp.wbBuf.reset() atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp)) } // 为 P 分配 cache 对象 if pp.mcache == nil { // 如果 old == 0 且 i == 0 说明这是引导阶段初始化第一个 p 。schedinit 中 mallocinit 有初始化一个 mcache if old == 0 && i == 0 { // 确认当前 g 的 m 的 mcache 非空 if getg().m.mcache == nil { throw("missing mcache?") } pp.mcache = getg().m.mcache // bootstrap } else { pp.mcache = allocmcache() } } // 如果 启动了 race 并且 racectx 为 0,则新建 if raceenabled && pp.racectx == 0 { // 如果 old == 0 且 i == 0 说明这是引导阶段初始化第一个 p 。 schedinit 中有初始化一个 raceproccreate if old == 0 && i == 0 { pp.racectx = raceprocctx0 raceprocctx0 = 0// bootstrap } else { pp.racectx = raceproccreate() } } }
// free unused P's // 释放不用的 P for i := nprocs; i < old; i++ { p := allp[i] if trace.enabled && p == getg().m.p.ptr() { // moving to p[0], pretend that we were descheduled // and then scheduled again to keep the trace sane. // 移至 p[0] ,假装我们已被调度,然后再次调度以保持跟踪正常。 traceGoSched() traceProcStop(p) } // move all runnable goroutines to the global queue // 将所有的 runnable goroutines 移动到全局队列 sched.runq for p.runqhead != p.runqtail { // pop from tail of local queue // 从本地队列的尾部 pop p.runqtail-- gp := p.runq[p.runqtail%uint32(len(p.runq))].ptr() // push onto head of global queue // push 到全局队列的头部 globrunqputhead(gp) } // 如果 runnext 不为 0,也加入到全局队列 sched.runq if p.runnext != 0 { globrunqputhead(p.runnext.ptr()) p.runnext = 0 } // if there's a background worker, make it runnable and put // it on the global queue so it can clean itself up // 如果存在 gc 后台 worker,则让其 runnable 并将其放到全局队列中从而可以让其对自身进行清理 if gp := p.gcBgMarkWorker.ptr(); gp != nil { casgstatus(gp, _Gwaiting, _Grunnable) if trace.enabled { traceGoUnpark(gp, 0) } globrunqput(gp) // This assignment doesn't race because the // world is stopped. // 此赋值不会发生竞争,因为此时已经 STW p.gcBgMarkWorker.set(nil) } // Flush p's write barrier buffer. // 刷新 p 的写屏障缓存 if gcphase != _GCoff { wbBufFlush1(p) p.gcw.dispose() } // 设置 sudogbuf for i := range p.sudogbuf { p.sudogbuf[i] = nil } p.sudogcache = p.sudogbuf[:0] for i := range p.deferpool { for j := range p.deferpoolbuf[i] { p.deferpoolbuf[i][j] = nil } p.deferpool[i] = p.deferpoolbuf[i][:0] } // 释放当前 P 绑定的 mcache freemcache(p.mcache) p.mcache = nil // 将当前 P 的 G 复链转移到全局 gfpurge(p) traceProcFree(p) if raceenabled { raceprocdestroy(p.racectx) p.racectx = 0 } p.gcAssistTime = 0 p.status = _Pdead // can't free P itself because it can be referenced by an M in syscall // 不能释放 P 本身,因为它可能被系统调用的 M 引用。 }
_g_ := getg() if _g_.m.p != 0 && _g_.m.p.ptr().id < nprocs { // 当前的 P 不需要被释放 // continue to use the current P // 继续使用当前 P _g_.m.p.ptr().status = _Prunning _g_.m.p.ptr().mcache.prepareForSweep() } else { // release the current P and acquire allp[0] // 释放当前 P,然后获取 allp[0] // p 和 m 解绑 if _g_.m.p != 0 { _g_.m.p.ptr().m = 0 } _g_.m.p = 0 _g_.m.mcache = nil // 更换到 allp[0] p := allp[0] p.m = 0 p.status = _Pidle acquirep(p) // 直接将 allp[0] 绑定到当前的 M if trace.enabled { traceGoStart() } } var runnablePs *p for i := nprocs - 1; i >= 0; i-- { p := allp[i] // 确保不是当前正在使用的 P if _g_.m.p.ptr() == p { continue }
// 将 p 设为 _Pidle p.status = _Pidle
// 本地任务列表是否为空 if runqempty(p) { // 放入 idle 链表 pidleput(p) } else { // 如果有本地任务,则为其绑定一个 M(不一定能获取到) p.m.set(mget()) // 第一个循环为 nil,后续则为上一个 p,此处即为构建可运行的 p 链表 p.link.set(runnablePs) runnablePs = p } } stealOrder.reset(uint32(nprocs)) var int32p *int32 = &gomaxprocs // make compiler check that gomaxprocs is an int32 // 让编译器检查 gomaxprocs 是 int32 类型 atomic.Store((*uint32)(unsafe.Pointer(int32p)), uint32(nprocs)) // 让编译器检查 gomaxprocs 是 int32 类型 return runnablePs }
// Associate p and the current m. // // This function is allowed to have write barriers even if the caller // isn't because it immediately acquires _p_. // 将 p 关联到当前的 m 。因为该函数会立即 acquire P,因此即使调用方不允许 write barrier,此函数仍然允许 write barrier。 // //go:yeswritebarrierrec funcacquirep(_p_ *p) { // Do the part that isn't allowed to have write barriers. // 此处不允许 write barrier 。关联了当前的 M 到 P 上。 wirep(_p_)
// Have p; write barriers now allowed. // 已经获取了 p,因此之后允许 write barrier
// Perform deferred mcache flush before this P can allocate // from a potentially stale mcache. // 在此 P 可以从可能过时的 mcache 分配前执行延迟的 mcache flush _p_.mcache.prepareForSweep()
if trace.enabled { traceProcStart() } }
// wirep is the first step of acquirep, which actually associates the // current M to _p_. This is broken out so we can disallow write // barriers for this part, since we don't yet have a P. // wirep 为 acquirep 的实际获取 p 的第一步,它关联了当前的 M 到 P 上。 我们在这部分使用 write barriers 被打破了,因为我们还没有P。 // //go:nowritebarrierrec //go:nosplit funcwirep(_p_ *p) { _g_ := getg()
// 如果当前的 m 已经关联了 p if _g_.m.p != 0 || _g_.m.mcache != nil { throw("wirep: already in go") } // 如果 _p_ 已经关联了 m , 且 _p_ 的状态不是 _Pidle if _p_.m != 0 || _p_.status != _Pidle { id := int64(0) if _p_.m != 0 { id = _p_.m.ptr().id } print("wirep: p->m=", _p_.m, "(", id, ") p->status=", _p_.status, "\n") throw("wirep: invalid p state") } // 关联当前 m 和 _p_ , 并设置 _p_ 为 _Prunning _g_.m.mcache = _p_.mcache // 使用 p 的 mcache _g_.m.p.set(_p_) // 将 p 关联到到 m _p_.m.set(_g_.m) // 将 m 关联到到 p _p_.status = _Prunning // 设置 _Prunning }
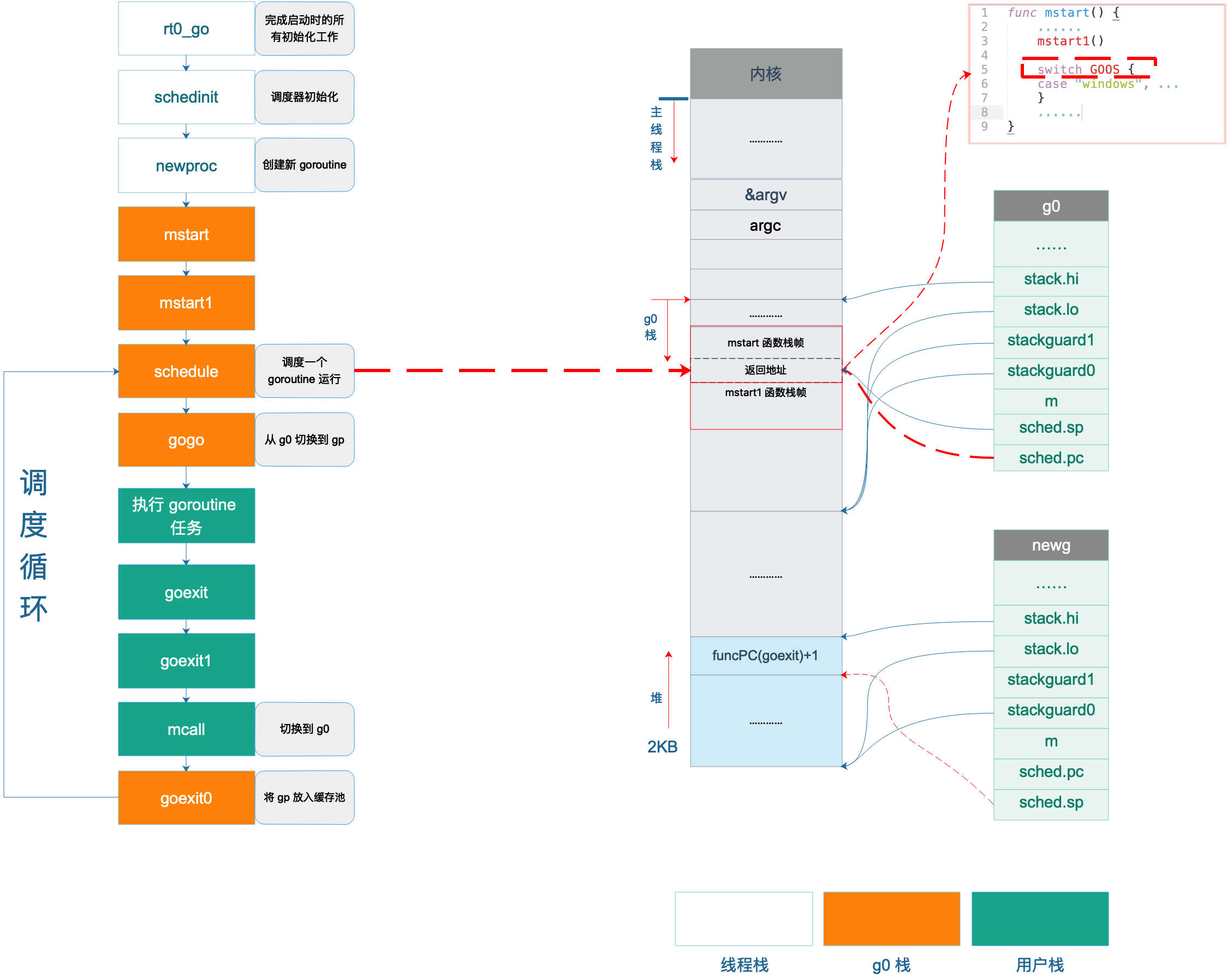
// src/runtime/proc.go // Called to start an M. // // This must not split the stack because we may not even have stack // bounds set up yet. // // May run during STW (because it doesn't have a P yet), so write // barriers are not allowed. // 启动 M , M 的入口函数 // 该函数不允许分段栈,因为我们甚至还没有设置栈的边界。它可能会在 STW 阶段运行(因为它还没有 P),所以 write barrier 也是不允许的 // //go:nosplit //go:nowritebarrierrec funcmstart() { _g_ := getg()
// 确定执行栈的边界。通过检查 g 执行占的边界来确定是否为系统栈 osStack := _g_.stack.lo == 0 if osStack { // Initialize stack bounds from system stack. // Cgo may have left stack size in stack.hi. // minit may update the stack bounds. // 根据系统栈初始化执行栈的边界。cgo 可能会离开 stack.hi 。minit 可能会更新栈的边界 size := _g_.stack.hi if size == 0 { size = 8192 * sys.StackGuardMultiplier } _g_.stack.hi = uintptr(noescape(unsafe.Pointer(&size))) _g_.stack.lo = _g_.stack.hi - size + 1024 } // Initialize stack guards so that we can start calling // both Go and C functions with stack growth prologues. // 初始化堆栈守卫,以便我们可以使用堆栈增长 prologue (序言) 开始调用Go和C函数。 _g_.stackguard0 = _g_.stack.lo + _StackGuard _g_.stackguard1 = _g_.stackguard0 // 启动 M mstart1()
// Exit this thread. // 退出线程 if GOOS == "windows" || GOOS == "solaris" || GOOS == "plan9" || GOOS == "darwin" || GOOS == "aix" { // Window, Solaris, Darwin, AIX and Plan 9 always system-allocate // the stack, but put it in _g_.stack before mstart, // so the logic above hasn't set osStack yet. // Window,Solaris,Darwin,AIX和Plan 9始终对栈进行系统分配,但将其放在mstart之前的_g_.stack中,因此上述逻辑尚未设置osStack。 osStack = true } // 退出线程 mexit(osStack) }
mstart 主要获取当前的 g ,然后设置 stackguard0 , stackguard1 ,然后直接调用 mstart1 了。
// 检查当前执行的 g 是不是 g0 if _g_ != _g_.m.g0 { throw("bad runtime·mstart") }
// Record the caller for use as the top of stack in mcall and // for terminating the thread. // We're never coming back to mstart1 after we call schedule, // so other calls can reuse the current frame. // 这里会记录前一个调用者的状态, 包含 PC , SP 以及其他信息。这份记录会当作最初栈 (top stack),给之后的 mcall 调用,也用来结束那个线程。 // 接下來在 mstart1 调用到 schedule 之后就再也不会回到这个地方了,所以其他调用可以重用当前帧。
// 借助编译器的帮助获取 PC 和 SP , 然后在 save 中更新当前 G 的 sched (type gobuf) 的一些成员, 保存调用者的 pc 和 sp ,让日后其他执行者执行 gogo 函数的时候使用。 save(getcallerpc(), getcallersp()) asminit() // 初始化汇编,但是 amd64 架构下不需要执行任何代码就立刻返回,其他像是 arm、386 才有一些需在这里设定一些 CPU 相关的內容。 minit() // 初始化m 包括信号栈和信号掩码,procid
// Install signal handlers; after minit so that minit can // prepare the thread to be able to handle the signals. // 设置信号 handler ;在 minit 之后,因为 minit 可以准备处理信号的的线程 if _g_.m == &m0 { // 在当前的 goroutine 的所属执行者是 m0 的情況下进入 mstartm0 函数,正式启动在此之前的 signal 处理设定,其中最关键的是 initsig 函数。 mstartm0() }
// 如果当前 m 并非 m0,则要求绑定 p if _g_.m != &m0 { acquirep(_g_.m.nextp.ptr()) _g_.m.nextp = 0 }
// 彻底准备好,开始调度,永不返回 schedule() }
// mstartm0 implements part of mstart1 that only runs on the m0. // // Write barriers are allowed here because we know the GC can't be // running yet, so they'll be no-ops. // // mstartm0 实现了一部分 mstart1,只运行在 m0 上。允许 write barrier,因为我们知道 GC 此时还不能运行,因此他们没有操作。 //go:yeswritebarrierrec funcmstartm0() { // Create an extra M for callbacks on threads not created by Go. // An extra M is also needed on Windows for callbacks created by // syscall.NewCallback. See issue #6751 for details. // 创建一个额外的 M 处理 non-Go 线程(cgo 调用中产生的线程)的回调,并且只创建一个。windows 上也需要额外 M 来处理 syscall.NewCallback 产生的回调,见 issue #6751 if (iscgo || GOOS == "windows") && !cgoHasExtraM { cgoHasExtraM = true newextram() } // 初始化信号。 initsig(false) }
// save updates getg().sched to refer to pc and sp so that a following // gogo will restore pc and sp. // // save must not have write barriers because invoking a write barrier // can clobber getg().sched. // save 更新了 getg().sched 的 pc 和 sp 的指向,并允许 gogo 能够恢复到 pc 和 sp 。 save 不允许 write barrier, 因为会破坏 getg().sched 。 // //go:nosplit //go:nowritebarrierrec funcsave(pc, sp uintptr) { _g_ := getg()
_g_.sched.pc = pc _g_.sched.sp = sp _g_.sched.lr = 0 _g_.sched.ret = 0 _g_.sched.g = guintptr(unsafe.Pointer(_g_)) // We need to ensure ctxt is zero, but can't have a write // barrier here. However, it should always already be zero. // Assert that. // 我们必须确保 ctxt 为零,但这里不允许 write barrier。 所以这里只是做一个断言。 if _g_.sched.ctxt != nil { badctxt() } }
首先调用 save 函数来保存 g0 的调度信息。save 函数执行完成后,继续其它跟 m 相关的一些初始化,然后调用调度系统的核心函数 schedule() 完成 goroutine 的调度,每次调度 goroutine 都是从 schedule 函数开始的。
// src/runtime/proc.go // One round of scheduler: find a runnable goroutine and execute it. // Never returns. // 调度器的一轮:找到 runnable goroutine 并进行执行且永不返回。 funcschedule() { _g_ := getg()
// 调度的时候, m 不能持有 locks if _g_.m.locks != 0 { throw("schedule: holding locks") }
// 如果当前 M 锁定了某个 G ,那么应该交出P,进入休眠。等待某个 M 调度拿到 lockedg ,然后唤醒 lockedg 的 M if _g_.m.lockedg != 0 { stoplockedm() // 停止当前正在执行锁住的 g 的 m 的执行,直到 g 重新变为 runnable , 被唤醒 。 返回时关联了 P execute(_g_.m.lockedg.ptr(), false) // Never returns. }
// We should not schedule away from a g that is executing a cgo call, // since the cgo call is using the m's g0 stack. // 我们不应该调度一个正在执行 cgo 调用的 g , 因为 cgo 在使用当前 m 的 g0 栈 if _g_.m.incgo { throw("schedule: in cgo") }
top: // 如果当前 GC 需要(STW), 则调用 gcstopm 休眠当前的 M if sched.gcwaiting != 0 { gcstopm() goto top } // 如果有安全点函数, 则执行 if _g_.m.p.ptr().runSafePointFn != 0 { runSafePointFn() }
var gp *g var inheritTime bool // 如果启动 trace 或等待 trace reader if trace.enabled || trace.shutdown { // 有 trace reader 需要被唤醒则标记 _Grunnable gp = traceReader() if gp != nil { casgstatus(gp, _Gwaiting, _Grunnable) traceGoUnpark(gp, 0) } } // 如果当前 GC 正在标记阶段,允许置黑对象,则查找有没有待运行的 GC Worker, GC Worker 也是一个 G if gp == nil && gcBlackenEnabled != 0 { gp = gcController.findRunnableGCWorker(_g_.m.p.ptr()) } // 说明不在 gc if gp == nil { // Check the global runnable queue once in a while to ensure fairness. // Otherwise two goroutines can completely occupy the local runqueue // by constantly respawning each other. // 每调度 61 次,就检查一次全局队列,保证公平性。否则两个 goroutine 可以通过不断地互相 respawn(重生) 一直占领本地的 runqueue if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 { lock(&sched.lock) gp = globrunqget(_g_.m.p.ptr(), 1) unlock(&sched.lock) } } if gp == nil { // 从p的本地队列中获取 gp, inheritTime = runqget(_g_.m.p.ptr()) // 本地有 g ,则 m 不应该在 spinning 状态 if gp != nil && _g_.m.spinning { throw("schedule: spinning with local work") } } if gp == nil { // 想尽办法找到可运行的 G ,找不到就不用返回了 gp, inheritTime = findrunnable() // blocks until work is available }
// 这个时候肯定取到 g 了
// This thread is going to run a goroutine and is not spinning anymore, // so if it was marked as spinning we need to reset it now and potentially // start a new spinning M. // 该线程将运行 goroutine ,并且不再 spinning ,因此,如果将其标记为 spinning ,则需要立即将其重置并可能启动新的 spinning M 。 if _g_.m.spinning { // 如果 m 是 spinning 状态,则: // 1. 从 spinning -> non-spinning // 2. 在没有 spinning 的 m 的情况下,再多创建一个新的 spinning m resetspinning() }
// 如果禁用用户地 G 调度,并且 gp 不能够调度, 表示 gp 是用户 G ,不是系统 G if sched.disable.user && !schedEnabled(gp) { // Scheduling of this goroutine is disabled. Put it on // the list of pending runnable goroutines for when we // re-enable user scheduling and look again. // 禁用此 goroutine 的调度。 当我们重新启用用户调度并再次查看时,将其放在待处理的可运行 goroutine 列表中。 lock(&sched.lock) // 锁住后重新检测 if schedEnabled(gp) { // Something re-enabled scheduling while we // were acquiring the lock. // 当我们之前正在获取锁的时候,可能有什么重新启动了调度, 也就是锁住之前,可能哪里重新启动了用户 g 调度。 unlock(&sched.lock) } else { // 加入到禁用掉的等待的可运行的 G 队尾 sched.disable.runnable.pushBack(gp) sched.disable.n++ unlock(&sched.lock) goto top } }
// 如果 gp 锁定了 m if gp.lockedm != 0 { // Hands off own p to the locked m, // then blocks waiting for a new p. // 让出 gp 给其锁定的 m ,然后阻塞等待新的 p startlockedm(gp) // 调度锁定的 m 来运行锁定的 gp goto top }
// 开始执行 execute(gp, inheritTime) }
// Finds a runnable goroutine to execute. // Tries to steal from other P's, get g from global queue, poll network. // 寻找一个可运行的 goroutine 来执行。尝试从其他的 P 偷取、从本地或者全局队列中获取、pollnet 。 funcfindrunnable()(gp *g, inheritTime bool) { _g_ := getg()
// The conditions here and in handoffp must agree: if // findrunnable would return a G to run, handoffp must start // an M. // 这里的条件与 handoffp 中的条件必须一致:如果 findrunnable 将返回 G 来运行,handoffp 必须启动 M 。
top: _p_ := _g_.m.p.ptr() if sched.gcwaiting != 0 { gcstopm() // 如果在 gc,则 park 当前 m,直到被 unpark 后回到 top goto top } if _p_.runSafePointFn != 0 { runSafePointFn() // 如果需要执行安全点函数,则执行 } if fingwait && fingwake { if gp := wakefing(); gp != nil { ready(gp, 0, true) } } // cgo 调用被终止,继续进入 if *cgo_yield != nil { asmcgocall(*cgo_yield, nil) }
// local runq // 取本地队列 local runq,如果已经拿到,立刻返回 if gp, inheritTime := runqget(_p_); gp != nil { return gp, inheritTime }
// global runq // 全局队列 global runq,如果已经拿到,立刻返回 if sched.runqsize != 0 { lock(&sched.lock) gp := globrunqget(_p_, 0) unlock(&sched.lock) if gp != nil { return gp, false } }
// Poll network. // This netpoll is only an optimization before we resort to stealing. // We can safely skip it if there are no waiters or a thread is blocked // in netpoll already. If there is any kind of logical race with that // blocked thread (e.g. it has already returned from netpoll, but does // not set lastpoll yet), this thread will do blocking netpoll below // anyway. // Poll 网络,优先级比从其他 P 中偷要高。在我们尝试去其他 P 偷之前,这个 netpoll 只是一个优化。如果没有 waiter 或 netpoll 中的线程已被阻塞, // 则可以安全地跳过它。如果有任何类型的逻辑竞争与被阻塞的线程(例如它已经从 netpoll 返回,但尚未设置 lastpoll),该线程无论如何都将阻塞 netpoll 。 // netpoll 已经初始化了,并且没有在等待 netpoll 的 g ,并且 sched.lastpoll != 0 , 下面候可能将 sched.lastpoll 设置为 0 ,然后阻塞调用 // netpoll(true),返回后才设置 lastpoll , 如果 sched.lastpoll == 0 的话,则表示 netpoll 还在阻塞, 这时候是 netpool 没有就绪 g 的。 if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 { // 轮询就绪的网络链接,查找 runnable G if list := netpoll(false); !list.empty() { // non-blocking gp := list.pop() // 获取一个 injectglist(&list) // 将 netpool 中剩余的 runnable g 列表插入到调度器中 casgstatus(gp, _Gwaiting, _Grunnable) // 设置状态为 _Grunnable if trace.enabled { traceGoUnpark(gp, 0) } // 返回从 netpoll 中窃取到的 g return gp, false } }
// Steal work from other P's. // 从其他 P 中窃取 work procs := uint32(gomaxprocs) if atomic.Load(&sched.npidle) == procs-1 { // Either GOMAXPROCS=1 or everybody, except for us, is idle already. // New work can appear from returning syscall/cgocall, network or timers. // Neither of that submits to local run queues, so no point in stealing. // GOMAXPROCS=1 或除我们之外的每个 P 都空闲。 通过返回 syscall/cgocall,network 或 timers,可以找到新 P。 // 两者都不会提交到本地运行队列,因此在窃取方面毫无意义。 goto stop } // If number of spinning M's >= number of busy P's, block. // This is necessary to prevent excessive CPU consumption // when GOMAXPROCS>>1 but the program parallelism is low. // 如果 spinning 状态下 m 的数量 >= busy 状态下 p 的数量,直接进入阻塞。该步骤是有必要的,它用于当 GOMAXPROCS>>1 时 // 但程序的并行机制很慢时昂贵的 CPU 消耗。 if !_g_.m.spinning && 2*atomic.Load(&sched.nmspinning) >= procs-atomic.Load(&sched.npidle) { goto stop } // 如果 m 是 non-spinning 状态,切换为 spinning if !_g_.m.spinning { _g_.m.spinning = true atomic.Xadd(&sched.nmspinning, 1) } for i := 0; i < 4; i++ { // 随机窃取 for enum := stealOrder.start(fastrand()); !enum.done(); enum.next() { if sched.gcwaiting != 0 { goto top // 已经进入了 GC? 回到 top ,park 当前的 m } // 如果偷了3次都偷不到,连 p.runnext (是当前G准备好的可运行G) 都窃取 stealRunNextG := i > 2// first look for ready queues with more than 1 g if gp := runqsteal(_p_, allp[enum.position()], stealRunNextG); gp != nil { // 窃取到了就返回 return gp, false } } }
stop:
// We have nothing to do. If we're in the GC mark phase, can // safely scan and blacken objects, and have work to do, run // idle-time marking rather than give up the P. // 没有任何 work 可做。如果我们在 GC mark 阶段,则可以安全的扫描并 blacken 对象,然后便有 work 可做,运行 idle-time 标记而非直接放弃当前的 P。 if gcBlackenEnabled != 0 && _p_.gcBgMarkWorker != 0 && gcMarkWorkAvailable(_p_) { _p_.gcMarkWorkerMode = gcMarkWorkerIdleMode gp := _p_.gcBgMarkWorker.ptr() casgstatus(gp, _Gwaiting, _Grunnable) if trace.enabled { traceGoUnpark(gp, 0) } return gp, false }
// wasm only: // If a callback returned and no other goroutine is awake, // then pause execution until a callback was triggered. // 仅限于 wasm 。如果一个回调返回后没有其他 goroutine 是苏醒的。则暂停执行直到回调被触发。 if beforeIdle() { // At least one goroutine got woken. // 至少一个 goroutine 被唤醒 goto top }
// Before we drop our P, make a snapshot of the allp slice, // which can change underfoot once we no longer block // safe-points. We don't need to snapshot the contents because // everything up to cap(allp) is immutable. // 放弃当前的 P 之前,对 allp 做一个快照。一旦我们不再阻塞在 safe-point 时候,可以立刻在下面进行修改。 // 我们不需要对内容进行快照,因为 cap(allp) 的所有内容都是不可变的。 allpSnapshot := allp
// return P and block // 准备归还 p,对调度器加锁 lock(&sched.lock) // GC 或 运行安全点函数,则回到 top if sched.gcwaiting != 0 || _p_.runSafePointFn != 0 { unlock(&sched.lock) goto top } // 全局队列中又发现了 g if sched.runqsize != 0 { gp := globrunqget(_p_, 0) unlock(&sched.lock) return gp, false } // 取消关联 p 和当前 m if releasep() != _p_ { throw("findrunnable: wrong p") } // 将 p 放入 idle 链表 pidleput(_p_) // 完成归还,解锁 unlock(&sched.lock)
// Delicate dance: thread transitions from spinning to non-spinning state, // potentially concurrently with submission of new goroutines. We must // drop nmspinning first and then check all per-P queues again (with // #StoreLoad memory barrier in between). If we do it the other way around, // another thread can submit a goroutine after we've checked all run queues // but before we drop nmspinning; as the result nobody will unpark a thread // to run the goroutine. // If we discover new work below, we need to restore m.spinning as a signal // for resetspinning to unpark a new worker thread (because there can be more // than one starving goroutine). However, if after discovering new work // we also observe no idle Ps, it is OK to just park the current thread: // the system is fully loaded so no spinning threads are required. // Also see "Worker thread parking/unparking" comment at the top of the file. // 这里要非常小心: 线程从 spinning 到 non-spinning 状态的转换,可能与新 goroutine 的提交同时发生。 我们必须首先降低 nmspinning, // 然后再次检查所有的 per-P 队列(并在期间伴随 #StoreLoad 内存屏障)。如果反过来,其他线程可以在我们检查了所有的队列、然后提交一个 // goroutine、再降低 nmspinning ,进而导致无法 unpark 一个线程来运行那个 goroutine 了。 // 如果我们发现下面的新 work,我们需要恢复 m.spinning 作为重置的信号,以取消 park 新的工作线程(因为可能有多个饥饿的 goroutine)。 // 但是,如果在发现新 work 后我们也观察到没有空闲 P,可以暂停当前线程。因为系统已满载,因此不需要 spinning 线程。 // 请参考此文件顶部 "工作线程 parking/unparking" 的注释。 wasSpinning := _g_.m.spinning // 记录下之前的状态是否为 spinning if _g_.m.spinning { // spinning 到 non-spinning 状态的转换,并递减 sched.nmspinning _g_.m.spinning = false ifint32(atomic.Xadd(&sched.nmspinning, -1)) < 0 { throw("findrunnable: negative nmspinning") } }
// check all runqueues once again // 再次检查所有的 runqueue for _, _p_ := range allpSnapshot { // 如果这时本地队列不空 if !runqempty(_p_) { // 锁住调度,重新获取空闲的 p lock(&sched.lock) _p_ = pidleget() unlock(&sched.lock) // 如果能获取到空闲的 p if _p_ != nil { // p 与当前 m 关联 acquirep(_p_) // 如果此前已经被切换为 spinning if wasSpinning { // 重新切换回 non-spinning _g_.m.spinning = true atomic.Xadd(&sched.nmspinning, 1) } // 这时候是有 work 的,回到顶部重新找 g goto top } // 没有空闲的 p,不需要重新找 g 了 break } }
// Check for idle-priority GC work again. // 再次检查 idle-priority GC work 。和上面重新找 runqueue 的逻辑类似 // gcMarkWorkAvailable 参数为 nil ,在这种情况下,它仅检查全局工作任务。 if gcBlackenEnabled != 0 && gcMarkWorkAvailable(nil) { lock(&sched.lock) // 获取空闲的 p _p_ = pidleget() if _p_ != nil && _p_.gcBgMarkWorker == 0 { // 获取到的 p 没有 background mask worker, 重新放回空闲 p 列表 pidleput(_p_) _p_ = nil } unlock(&sched.lock) // 如果能获取到空闲的 p if _p_ != nil { // p 与当前 m 关联 acquirep(_p_) // 如果此前已经被切换为 spinning if wasSpinning { // 重新切换回 non-spinning _g_.m.spinning = true atomic.Xadd(&sched.nmspinning, 1) } // Go back to idle GC check. // 这时候是有 work 的,回到顶部重新找 g goto stop } }
// poll network // poll 网络。和上面重新找 runqueue 的逻辑类似 // netpoll 已经初始化了,并且没有在等待 netpoll 的 g ,并且 sched.lastpoll != 0 ,满足的话,会设置 sched.lastpoll = 0 // atomic.Xchg64(&sched.lastpoll, 0) 设置 sched.lastpoll = 0 , 并返回原来的 sched.lastpoll if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Xchg64(&sched.lastpoll, 0) != 0 { if _g_.m.p != 0 { throw("findrunnable: netpoll with p") } if _g_.m.spinning { throw("findrunnable: netpoll with spinning") } list := netpoll(true) // block until new work is available // 阻塞直到有新的 work atomic.Store64(&sched.lastpoll, uint64(nanotime())) // 存储上一次 netpool 时间 // netpoll 的 g list 不会空 if !list.empty() { lock(&sched.lock) // 获取空闲的 p _p_ = pidleget() unlock(&sched.lock) // 如果能获取到空闲的 p if _p_ != nil { // p 与当前 m 关联 acquirep(_p_) gp := list.pop() // 获取一个 injectglist(&list) // 将 netpool 中剩余的 runnable g 列表插入到调度器中 casgstatus(gp, _Gwaiting, _Grunnable) // 设置状态为 _Grunnable if trace.enabled { traceGoUnpark(gp, 0) } // 返回从 netpoll 中窃取到的 g return gp, false } // 如果没有获取到 p ,将 netpool 中获取到的 runnable g 列表插入到调度器中 injectglist(&list) } } // 确实找不到,park 当前的 m stopm() // m unpark 后继续找 goto top }
schedule 大致的执行流程是:
如果当前 M 锁定了某个 G ,那么应该交出P,进入休眠。等待某个 M 调度拿到 lockedg ,然后唤醒 lockedg 的 M
如果当前 GC 需要(STW), 则调用 gcstopm 休眠当前的 M
如果有安全点函数, 则执行
找一个 g 来执行,找 g 的过程大致如下:
如果当前 GC 正在标记阶段,允许置黑对象,则查找有没有待运行的 GC Worker, GC Worker 也是一个 G
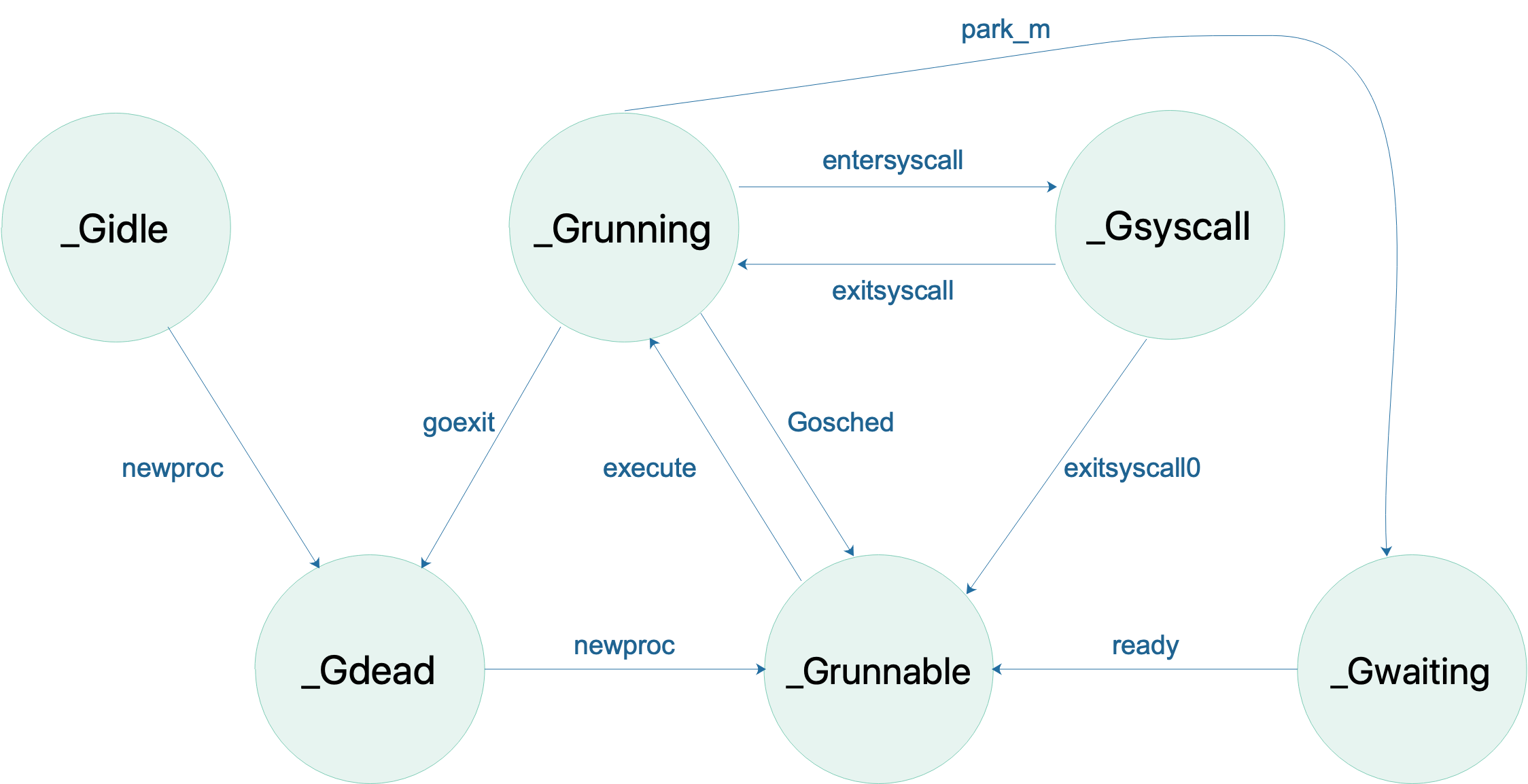
// Schedules gp to run on the current M. // If inheritTime is true, gp inherits the remaining time in the // current time slice. Otherwise, it starts a new time slice. // Never returns. // // Write barriers are allowed because this is called immediately after // acquiring a P in several places. // // 在当前 M 上调度 gp。 如果 inheritTime 为 true,则 gp 继承剩余的时间片。否则从一个新的时间片开始。 此函数永不返回。 // 该函数允许 write barrier 因为它是在 acquire P 之后的调用的。 // //go:yeswritebarrierrec funcexecute(gp *g, inheritTime bool) { _g_ := getg()
// 将 g 正式切换为 _Grunning 状态 casgstatus(gp, _Grunnable, _Grunning) gp.waitsince = 0// 清除等待时间,现在开始执行了 gp.preempt = false// 关闭抢占 gp.stackguard0 = gp.stack.lo + _StackGuard // 设置栈边界检测 if !inheritTime { // 如果不继承时间片,则开始新的 _g_.m.p.ptr().schedtick++ } _g_.m.curg = gp // 设置当前循运行的 g gp.m = _g_.m // 设置运行的g的 m
// Check whether the profiler needs to be turned on or off. // 检查是否需要打开或关闭 cpu profiler 。 hz := sched.profilehz if _g_.m.profilehz != hz { setThreadCPUProfiler(hz) }
// trace if trace.enabled { // GoSysExit has to happen when we have a P, but before GoStart. // So we emit it here. if gp.syscallsp != 0 && gp.sysblocktraced { traceGoSysExit(gp.sysexitticks) } traceGoStart() }
// src/runtime/proc.go // The main goroutine. // 主 goroutine,也就是runtime·mainPC funcmain() { // 获取当前的G, G为TLS(Thread Local Storage) g := getg()
···
// Max stack size is 1 GB on 64-bit, 250 MB on 32-bit. // Using decimal instead of binary GB and MB because // they look nicer in the stack overflow failure message. // 执行栈的最大限制: 1GB on 64-bit, 250 MB on 32-bit。使用十进制而不是二进制GB和MB,因为它们在堆栈溢出失败消息中好看些。 if sys.PtrSize == 8 { maxstacksize = 1000000000 } else { maxstacksize = 250000000 }
// Allow newproc to start new Ms. // 表示main goroutine启动了,接下来允许 newproc 启动新的 m mainStarted = true
···
// 执行 runtime.main 函数的 G 必须是绑定在 m0 上的 if g.m != &m0 { throw("runtime.main not on m0") }
// 执行初始化运行时 runtime_init() // must be before defer // defer 必须在此调用结束后才能使用 if nanotime() == 0 { throw("nanotime returning zero") }
···
main_init_done = make(chanbool)
···
// 执行 main_init,进行间接调用,因为链接器在设定运行时的时候不知道 main 包的地址 fn := main_init // make an indirect call, as the linker doesn't know the address of the main package when laying down the runtime fn() close(main_init_done)
needUnlock = false unlockOSThread()
···
// 执行用户 main 包中的 main 函数,处理为非间接调用,因为链接器在设定运行时不知道 main 包的地址 fn = main_main // make an indirect call, as the linker doesn't know the address of the main package when laying down the runtime fn()
··· // 退出执行,返回退出状态码 exit(0)
··· }
runtime·main 限制了最大栈(近似 1GB on 64-bit, 250 MB on 32-bit),结合前面的,我们就知道了, go 动态栈的范围是 2KB 到 1GB/250MB 。然后 fn = main_main ; fn() 终于执行到用户代码了,真不容易啊!然后直接调用 exit 结束进程了。注意这里是 main goroutine !
// src/runtime/asm_amd64.s // The top-most function running on a goroutine // returns to goexit+PCQuantum. // 在 goroutine 上运行的最顶层函数将返回goexit + PCQuantum。 // goroutine 执行完成后返回后执行: CALL runtime·goexit1(SB) TEXT runtime·goexit(SB),NOSPLIT,$0-0 BYTE $0x90// NOP CALL runtime·goexit1(SB) // does not return // 永不返回 // traceback from goexit1 must hit code range of goexit BYTE $0x90// NOP
// src/runtime/proc.go // Finishes execution of the current goroutine. // 完成当前 goroutine 的执行 funcgoexit1() { if raceenabled { racegoend() } if trace.enabled { traceGoEnd() } // 开始收尾工作 mcall(goexit0) }
// 切换当前的 g 为 _Gdead casgstatus(gp, _Grunning, _Gdead) // 如果是系统 g , 更新统计信息 if isSystemGoroutine(gp, false) { atomic.Xadd(&sched.ngsys, -1) } // 清理 gp.m = nil locked := gp.lockedm != 0 gp.lockedm = 0 _g_.m.lockedg = 0 gp.paniconfault = false gp._defer = nil// should be true already but just in case. // 应该已经为 true,但以防万一 gp._panic = nil// non-nil for Goexit during panic. points at stack-allocated data. // Goexit 中 panic 则不为 nil, 指向栈分配的数据 gp.writebuf = nil gp.waitreason = 0 gp.param = nil gp.labels = nil gp.timer = nil
if gcBlackenEnabled != 0 && gp.gcAssistBytes > 0 { // Flush assist credit to the global pool. This gives // better information to pacing if the application is // rapidly creating an exiting goroutines. // 刷新 assist credit 到全局池。如果政协在快速创建已存在的 goroutine,这可以为 pacing 提供更好的信息。 scanCredit := int64(gcController.assistWorkPerByte * float64(gp.gcAssistBytes)) atomic.Xaddint64(&gcController.bgScanCredit, scanCredit) gp.gcAssistBytes = 0 }
// Note that gp's stack scan is now "valid" because it has no // stack. // 请注意, gp 的栈扫描现在 “有效” ,因为它没有栈。 gp.gcscanvalid = true // 移除 m 与当前 goroutine m->curg 之间的关联 dropg()
if GOARCH == "wasm" { // no threads yet on wasm // wasm 目前还没有线程支持 gfput(_g_.m.p.ptr(), gp) // 将 g 放进 gfree 链表中等待复用 schedule() // never returns }
// lockOSThread/unlockOSThread 调用不匹配 if _g_.m.lockedInt != 0 { print("invalid m->lockedInt = ", _g_.m.lockedInt, "\n") throw("internal lockOSThread error") } gfput(_g_.m.p.ptr(), gp) // 将 g 放进 gfree 链表中等待复用 if locked { // The goroutine may have locked this thread because // it put it in an unusual kernel state. Kill it // rather than returning it to the thread pool. // 该 goroutine 可能在当前线程上锁住,因为它可能导致了不正常的内核状态。这时候 kill 该线程,而非将 m 放回到线程池。
// Return to mstart, which will release the P and exit // the thread. // 此举会返回到 mstart,从而释放当前的 P 并退出该线程 if GOOS != "plan9" { // See golang.org/issue/22227. // mstart1 调用 save 保存的,这里恢复,则结束线程 gogo(&_g_.m.g0.sched) } else { // Clear lockedExt on plan9 since we may end up re-using // this thread. // 因为我们可能已重用此线程结束,在 plan9 上清除 lockedExt _g_.m.lockedExt = 0 } } // 再次进行调度 schedule() }