// src/runtime/runtime2.go type g struct { // Stack parameters. // stack describes the actual stack memory: [stack.lo, stack.hi). // stackguard0 is the stack pointer compared in the Go stack growth prologue. // It is stack.lo+StackGuard normally, but can be StackPreempt to trigger a preemption. // stackguard1 is the stack pointer compared in the C stack growth prologue. // It is stack.lo+StackGuard on g0 and gsignal stacks. // It is ~0 on other goroutine stacks, to trigger a call to morestackc (and crash). // Stack 参数 // stack 描述了实际的栈内存:[stack.lo, stack.hi) // stackguard0 是对比 Go 栈增长的 prologue 的栈指针,如果 sp 寄存器比 stackguard0 小(由于栈往低地址方向增长),会触发栈拷贝和调度 // 通常情况下:stackguard0 = stack.lo + StackGuard,但被抢占时会变为 StackPreempt。 // stackguard1 是对比 C 栈增长的 prologue 的栈指针,当位于 g0 和 gsignal 栈上时,值为 stack.lo + StackGuard // 在其他栈上值为 ~0 用于触发 morestackc (并 crash) 调用 // // prologue (序言) 函数是函数开头的几行代码,它们准备了堆栈和寄存器以供在函数内使用。 epilogue (尾声) 函数出现在函数的末尾,并将堆栈和寄存器恢复到调用函数之前的状态。 // prologue/epilogue 参见:https://en.wikipedia.org/wiki/Function_prologue // // 编译器会在有栈溢出风险的函数开头加如 一些代码(也就是prologue),会比较 SP (栈寄存器,指向栈顶) 和 stackguard0,如果 SP 的值更小,说明当前 g 的栈要用完了, // 有溢出风险,需要调用 morestack_noctxt 函数来扩栈,morestack_noctxt()->morestack()->newstack() ,newstack中会处理抢占(preempt)。参见 asm_amd64.s,stack.go stack stack // offset known to runtime/cgo // 当前g使用的栈空间, 有lo和hi两个成员 stackguard0 uintptr// offset known to liblink // stackguard0 = stack.lo + StackGuard ,检查栈空间是否足够的值, 低于这个值会扩张栈, 用于 GO 的 stack overlow的检测 stackguard1 uintptr// offset known to liblink // stackguard1 = stack.lo + StackGuard ,检查栈空间是否足够的值, 低于这个值会扩张栈, 用于 C 的 stack overlow的检测
_panic *_panic // innermost panic - offset known to liblink // 内部 panic ,偏移量用于 liblink _defer *_defer // innermost defer // 内部 defer m *m // current m; offset known to arm liblink // 当前 g 对应的 m ; 偏移量对 arm liblink 透明 sched gobuf // goroutine 的现场,g 的调度数据, 当 g 中断时会保存当前的 pc 和 sp 等值到这里, 恢复运行时会使用这里的值 syscallsp uintptr// if status==Gsyscall, syscallsp = sched.sp to use during gc // 如果 status==Gsyscall, 则 syscallsp = sched.sp 并在 GC 期间使用 syscallpc uintptr// if status==Gsyscall, syscallpc = sched.pc to use during gc // 如果 status==Gsyscall, 则 syscallpc = sched.pc 并在 GC 期间使用 stktopsp uintptr// expected sp at top of stack, to check in traceback // 期望 sp 位于栈顶,用于回溯检查 param unsafe.Pointer // passed parameter on wakeup // wakeup 唤醒时候传递的参数 atomicstatus uint32// g 的当前状态,原子性 stackLock uint32// sigprof/scang lock; TODO: fold in to atomicstatus // sigprof/scang锁,将会归入到atomicstatus goid int64// goroutine ID schedlink guintptr // 下一个 g , 当 g 在链表结构中会使用 waitsince int64// approx time when the g become blocked // g 阻塞的时间 waitreason waitReason // if status==Gwaiting // 如果 status==Gwaiting,则记录等待的原因 preempt bool// preemption signal, duplicates stackguard0 = stackpreempt // 抢占信号, g 是否被抢占中, stackguard0 = stackPreempt 的副本 paniconfault bool// panic (instead of crash) on unexpected fault address // 发生 fault panic (不崩溃)的地址 preemptscan bool// preempted g does scan for gc // 抢占式 g 会执行 GC scan gcscandone bool// g has scanned stack; protected by _Gscan bit in status // g 执行栈已经 scan 了;此此段受 _Gscan 位保护 gcscanvalid bool// false at start of gc cycle, true if G has not run since last scan; TODO: remove? // 在 gc 周期开始时为 false,如果自上次 scan 以来G没有运行,则为 true throwsplit bool// must not split stack // 必须不能进行栈分段 raceignore int8// ignore race detection events // 忽略 race 检查事件 sysblocktraced bool// StartTrace has emitted EvGoInSyscall about this goroutine // StartTrace 已经出发了此 goroutine 的 EvGoInSyscall sysexitticks int64// cputicks when syscall has returned (for tracing) // 当 syscall 返回时的 cputicks(用于跟踪) traceseq uint64// trace event sequencer // 跟踪事件排序器 tracelastp puintptr // last P emitted an event for this goroutine // 最后一个为此 goroutine 触发事件的 P lockedm muintptr // g 是否要求要回到这个 M 执行, 有的时候 g 中断了恢复会要求使用原来的 M 执行 sig uint32// 信号,参见 defs_linux_arm64.go : siginfo writebuf []byte// 写缓存 sigcode0 uintptr// 参见 siginfo sigcode1 uintptr// 参见 siginfo sigpc uintptr// 产生信号时的PC gopc uintptr// pc of go statement that created this goroutine // 当前创建 goroutine go 语句的 pc 寄存器 ancestors *[]ancestorInfo // ancestor information goroutine(s) that created this goroutine (only used if debug.tracebackancestors) // 创建此 goroutine 的 ancestor (祖先) goroutine 的信息(debug.tracebackancestors 调试用) startpc uintptr// pc of goroutine function // goroutine 函数的 pc 寄存器 racectx uintptr// 竟态上下文 waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order // 如果 g 发生阻塞(且有有效的元素指针)sudog 会将当前 g 按锁住的顺序组织起来 cgoCtxt []uintptr// cgo traceback context // cgo 回溯上下文 labels unsafe.Pointer // profiler labels // 分析器标签 timer *timer // cached timer for time.Sleep // 为 time.Sleep 缓存的计时器 selectDone uint32// are we participating in a select and did someone win the race? // 我们是否正在参与 select 且某个 goroutine 胜出
// Per-G GC state
// gcAssistBytes is this G's GC assist credit in terms of // bytes allocated. If this is positive, then the G has credit // to allocate gcAssistBytes bytes without assisting. If this // is negative, then the G must correct this by performing // scan work. We track this in bytes to make it fast to update // and check for debt in the malloc hot path. The assist ratio // determines how this corresponds to scan work debt. // gcAssistBytes 是该 G 在分配的字节数这一方面的的 GC 辅助 credit (信誉) // 如果该值为正,则 G 已经存入了在没有 assisting 的情况下分配了 gcAssistBytes 字节,如果该值为负,则 G 必须在 scan work 中修正这个值 // 我们以字节为单位进行追踪,一遍快速更新并检查 malloc 热路径中分配的债务(分配的字节)。assist ratio 决定了它与 scan work 债务的对应关系 gcAssistBytes int64 }
// src/runtime/runtime2.go type p struct { lock mutex // 锁
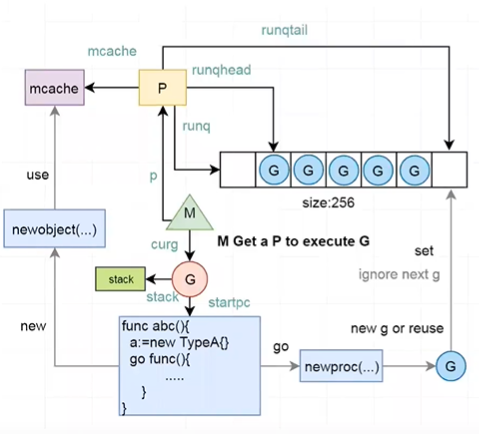
id int32// ID status uint32// one of pidle/prunning/... // 状态 link puintptr // p 的链表 schedtick uint32// incremented on every scheduler call // 每次调度程序调用时增加 syscalltick uint32// incremented on every system call // 每次系统调用时增加 sysmontick sysmontick // last tick observed by sysmon // sysmon观察到的最后一个tick,会记录 m muintptr // back-link to associated m (nil if idle) // 反向链接到相关的M(如果空闲则为nil) mcache *mcache // mcache: 每个P的内存缓存,不需要加锁 racectx uintptr// 竟态上下文
deferpool [5][]*_defer // pool of available defer structs of different sizes (see panic.go) // defer池,拥有不同的尺寸 deferpoolbuf [5][32]*_defer
// Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen. // goroutine ID的缓存将分摊对runtime.sched.goidgen的访问。 goidcache uint64 goidcacheend uint64
// Queue of runnable goroutines. Accessed without lock. // 可运行goroutine队列。 无锁访问。 // runqhead 和 runqtail 都是 uint32 ,不用担心越界问题,超过最大值之后,会变为 0 ,并且 0 - ^uint32(0) = 1 ,也就是说取长度也不会有问题。 runqhead uint32// 队头,runqhead 在后头跟,指向第一个可以使用,应该从这里取出 runqtail uint32// 队尾,runqtail 在队列前面走,指向第一个空槽,应该插入到这里 runq [256]guintptr // 运行队列 // runnext, if non-nil, is a runnable G that was ready'd by // the current G and should be run next instead of what's in // runq if there's time remaining in the running G's time // slice. It will inherit the time left in the current time // slice. If a set of goroutines is locked in a // communicate-and-wait pattern, this schedules that set as a // unit and eliminates the (potentially large) scheduling // latency that otherwise arises from adding the ready'd // goroutines to the end of the run queue. // runnext(如果不是nil)是当前G准备好的可运行G,如果正在运行的G的时间片中还有剩余时间,则应在下一个运行,而不是在runq中的G来运行。 // 它将继承当前时间片中剩余的时间。如果将一组goroutine锁定为“通信等待”模式,则将其设置为一个单元进行调度,并消除了(可能较大的)调度 // 延迟,而这种延迟可能是由于将就绪的goroutine添加到运行队列的末尾而引起的。 runnext guintptr
// Available G's (status == Gdead) // 可用的G,状态为Gdead gFree struct { gList n int32 }
// traceSweep indicates the sweep events should be traced. // This is used to defer the sweep start event until a span // has actually been swept. // traceSweep指示清扫事件是否被trace。这用于推迟清扫开始事件,直到实际扫过一个span为止。 traceSweep bool // traceSwept and traceReclaimed track the number of bytes // swept and reclaimed by sweeping in the current sweep loop. // traceSwept和traceReclaimed跟踪通过在当前清扫循环中进行清扫来清除和回收的字节数。 traceSwept, traceReclaimed uintptr
palloc persistentAlloc // per-P to avoid mutex // 分配器,每个P一个,避免加锁
// Per-P GC state // 每个P的GC状态 gcAssistTime int64// Nanoseconds in assistAlloc // gcAassistAlloc中计时 gcFractionalMarkTime int64// Nanoseconds in fractional mark worker // GC Mark计时 gcBgMarkWorker guintptr // 标记G gcMarkWorkerMode gcMarkWorkerMode // 标记模式
// gcMarkWorkerStartTime is the nanotime() at which this mark // worker started. gcMarkWorkerStartTime int64// mark worker启动时间
// gcw is this P's GC work buffer cache. The work buffer is // filled by write barriers, drained by mutator assists, and // disposed on certain GC state transitions. // gcw是此P的GC工作缓冲区高速缓存。工作缓冲区由写屏障填充,由辅助mutator(赋值器)耗尽,并放置在某些GC状态转换上。 gcw gcWork // GC 的本地工作队列,灰色对象管理
// wbBuf is this P's GC write barrier buffer. // // TODO: Consider caching this in the running G. // wbBuf 是当前 P 的 GC 的 write barrier 缓存 wbBuf wbBuf
runSafePointFn uint32// if 1, run sched.safePointFn at next safe point // 如果为 1, 则在下一个 safe-point 运行 sched.safePointFn
pad cpu.CacheLinePad }
gobuf
1 2 3 4 5 6 7 8 9 10 11
// src/runtime/runtime2.go // gobuf记录与协程切换相关信息 type gobuf struct { sp uintptr// sp 寄存器 pc uintptr// pc 寄存器 g guintptr // g 指针 ctxt unsafe.Pointer // 这个似乎是用来辅助 gc 的 ret sys.Uintreg // 作用 ? panic.go 中 recovery 函数有设置为 1 lr uintptr// 这是在 arm 上用的寄存器,不用关心 bp uintptr// for GOEXPERIMENT=framepointer // 开启 GOEXPERIMENT=framepointer ,才会有这个 }
// src/runtime/runtime2.go type m struct { g0 *g // goroutine with scheduling stack // 用于执行调度指令的 goroutine, 用于调度的特殊 g , 调度和执行系统调用时会切换到这个 g morebuf gobuf // gobuf arg to morestack // morestack 的 gobuf 参数 divmod uint32// div/mod denominator for arm - known to liblink
// Fields not known to debuggers. // debugger 不知道的字段 procid uint64// for debuggers, but offset not hard-coded // 用于 debugger,偏移量不是写死的 gsignal *g // signal-handling g // 用于 debugger,偏移量不是写死的 goSigStack gsignalStack // Go-allocated signal handling stack // Go 分配的 signal handling 栈 sigmask sigset // storage for saved signal mask // 用于保存 saved signal mask tls [6]uintptr// thread-local storage (for x86 extern register) // thread-local storage (对 x86 而言为额外的寄存器) mstartfn func() // M启动函数 curg *g // currentrunninggoroutine // 当前运行的用户 g caughtsigguintptr // goroutinerunningduringfatalsignal // goroutine 在 fatalsignal 中运行 ppuintptr // attachedpforexecutinggocode(nilif not executing go code) // 执行 go 代码时持有的 p(如果没有执行则为 nil) nextppuintptr // 下一个p, 唤醒 M 时, M 会拥有这个 P oldppuintptr // thepthatwasattachedbeforeexecutingasyscall // 执行系统调用之前绑定的 p idint64 // ID mallocingint32 // 是否正在分配内存 throwingint32 // 是否正在抛出异常 preemptoffstring // if != "", keepcurgrunningonthism // 如果不为空串 "",继续让当前 g 运行在该 M 上 locksint32 // M的锁 dyingint32 // 是否正在死亡,参见startpanic_m profilehzint32 // cpuprofilingrate spinningbool // misoutofworkandisactivelylookingforwork // m 当前没有运行 work 且正处于寻找 work 的活跃状态 blockedbool // misblockedonanote // m 阻塞在一个 note 上 inwbbool // misexecutingawritebarrier // m 在执行writebarrier newSigstackbool // minitonCthreadcalledsigaltstack // C 线程上的 minit 是否调用了 signalstack printlockint8 // print 锁,参见 print.goprintlock/printunlock incgobool // misexecutingacgocall // m 正在执行 cgo 调用 freeWaituint32 // if == 0, safetofreeg0anddeletem(atomic) // 如果为 0,安全的释放 g0 并删除 m(原子操作) fastrand [2]uint32 // 快速随机 needextrambool // 需要额外的 m tracebackuint8 // 回溯 ncgocalluint64 // numberofcgocallsintotal // 总共的 cgo 调用数 ncgoint32 // numberofcgocallscurrentlyinprogress // 正在进行的 cgo 调用数 cgoCallersUseuint32 // ifnon-zero, cgoCallersinusetemporarily // 如果非零,则表示 cgoCaller 正在临时使用 cgoCallers *cgoCallers // cgotracebackifcrashingincgocall // cgo 调用崩溃的 cgo 回溯 parknote // M 休眠时使用的信号量, 唤醒 M 时会通过它唤醒 alllink *m // onallm // 在 allm 上,将所有的 m 链接起来 schedlinkmuintptr // 下一个 m , 当 m 在链表结构中会使用 mcache *mcache // 分配内存时使用的本地分配器, 和 p.mcache 一样(拥有 P 时会复制过来) lockedgguintptr // 表示与当前 M 锁定的那个 G 。运行时系统会把 一个 M 和一个 G 锁定,一旦锁定就只能双方相互作用,不接受第三者。g.lockedm 的对应值 createstack [32]uintptr // stackthatcreatedthisthread.// 当前线程创建的栈 lockedExtuint32 // trackingforexternalLockOSThread // 外部 LockOSThread 追踪,LockOSThread/UnlockOSThread lockedIntuint32 // trackingforinternallockOSThread // 内部 lockOSThread 追踪,lockOSThread/unlockOSThread nextwaitmmuintptr // nextmwaitingforlock // 内部 lockOSThread 追踪 waitunlockfunsafe.Pointer // todogofunc(*g, unsafe.pointer)bool // 参见proc.gogopark waitlockunsafe.Pointer // 参见proc.gogopark waittraceevbyte // 参见proc.gogopark waittraceskipint // 参见proc.gogopark startingtracebool // 开始trace,见trace.goStartTrace syscalltickuint32 // 每次系统调用时增加 threaduintptr // threadhandle // 线程句柄 freelink *m // onsched.freem // 在 sched.freem 上 // theseareherebecausetheyaretoolargetobeonthestack // oflow-levelNOSPLITfunctions. // 下面这些字段因为它们太大而不能放在低级的 NOSPLIT 函数的堆栈上。 libcalllibcall // 调用信息 libcallpcuintptr // forcpuprofiler // 用于 cpuprofiler libcallspuintptr // libcallSP libcallgguintptr // libcallG syscalllibcall // storessyscallparametersonwindows // 存储 windows 上系统调用的参数 vdsoSPuintptr // SPfortracebackwhileinVDSOcall(0 if not in call) vdsoPCuintptr // PCfortracebackwhileinVDSOcall mOS }
// src/runtime/runtime2.go type schedt struct { // accessed atomically. keep at top to ensure alignment on 32-bit systems. // 原子访问,放到顶部,确保在32位系统上对齐(8字节)。 goidgen uint64// go runtime ID生成器,原子自增,在newproc1和oneNewExtraM中使用了 lastpoll uint64// 上一次轮询的时间(nanotime)
lock mutex // 锁
// When increasing nmidle, nmidlelocked, nmsys, or nmfreed, be // sure to call checkdead(). // 当增加nmidle,nmidlelocked,nmsys或nmfreed时,请确保调用checkdead()。
midle muintptr // idle m's waiting for work // 空闲的 M 队列 nmidle int32// number of idle m's waiting for work // 当前等待工作的空闲 M 计数 nmidlelocked int32// number of locked m's waiting for work // 当前等待工作的被 lock 的 M 计数 mnext int64// number of m's that have been created and next M ID // 已经被创建的 M 的数量,下一个 M 的 ID maxmcount int32// maximum number of m's allowed (or die) // 最大M的数量 nmsys int32// number of system m's not counted for deadlock // 系统 M 的数量, 在 deadlock 中不计数 nmfreed int64// cumulative number of freed m's // 释放的 M 的累计数量
ngsys uint32// number of system goroutines; updated atomically // 系统调用 goroutine 的数量,原子更新
// Global runnable queue. runq gQueue // 全局的 G 运行队列 runqsize int32// 全局的 G 运行队列大小
// disable controls selective disabling of the scheduler. // // Use schedEnableUser to control this. // // disable is protected by sched.lock. // disable控制选择性禁用调度程序。使用schedEnableUser进行控制。受sched.lock保护。 disable struct { // user disables scheduling of user goroutines. user bool// 用户禁用用户的goroutines调度 runnable gQueue // pending runnable Gs // 等待的可运行的G队列 n int32// length of runnable // runnable的长度 }
// Global cache of dead G's. // dead G全局缓存,已退出的 goroutine 对象缓存下来,避免每次创建 goroutine 时都重新分配内存,可参考proc.go中的gfput,gfget gFree struct { lock mutex // 锁 stack gList // Gs with stacks // 有堆栈的G noStack gList // Gs without stacks // 没有堆栈的G n int32// stack和noStack中的总数 }
// Central cache of sudog structs. sudoglock mutex // sudog缓存的锁 sudogcache *sudog // sudog缓存
// Central pool of available defer structs of different sizes. deferlock mutex // defer缓存的锁 deferpool [5]*_defer // defer缓存
// freem is the list of m's waiting to be freed when their // m.exited is set. Linked through m.freelink. freem *m // freem是设置 m.exited 时等待释放的 m 列表。通过 m.freelink 链接。
gcwaiting uint32// gc is waiting to run // GC等待运行 stopwait int32// 需要停止P的数目 stopnote note // stopwait睡眠唤醒事件 sysmonwait uint32// 等待系统监控 sysmonnote note // sysmonwait睡眠唤醒事件
// safepointFn should be called on each P at the next GC // safepoint if p.runSafePointFn is set. // 如果设置了p.runSafePointFn,则应在下一个GC安全点的每个P上调用safepointFn。 safePointFn func(*p) // 安全点函数 safePointWaitint32 // 等待safePointFn执行 safePointNotenote // safePointWait睡眠唤醒事件 profilehzint32 // cpuprofilingrate // CPU procresizetimeint64 // nanotime()oflastchangetogomaxprocs // 上一次修改gomaxprocs的时间,参见proc.go中的procresize totaltimeint64 // ∫gomaxprocsdtuptoprocresizetime // 总时间 }
Global objects
1 2 3 4 5 6 7 8 9 10 11 12 13
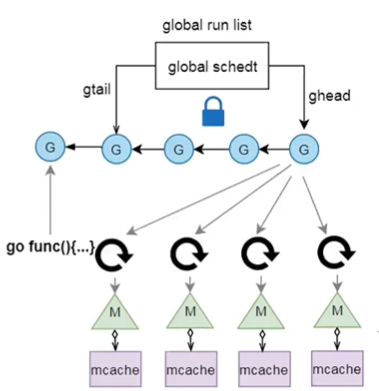
// src/runtime/runtime2.go // 全局的一些对象 var ( allglen uintptr// 所有G的数目 allm *m // 所有的M allp []*p // len(allp) == gomaxprocs; may change at safe points, otherwise immutable // 可能在安全区更改,否则不变 allpLock mutex // Protects P-less reads of allp and all writes // allp的锁 gomaxprocs int32// GOMAXPROCS ncpu int32// CPU数目 forcegc forcegcstate // 强制GC sched schedt // 调度 newprocs int32// GOMAXPROCS函数设置,startTheWorld处理 )
1 2 3 4 5
// src/runtime/proc.go var ( m0 m // 主M,asm_amd64.s中runtime·rt0_go初始化 g0 g // 主G,asm_amd64.s中runtime·rt0_go初始化 )